About the project#
Caution
This website is still a work in progress
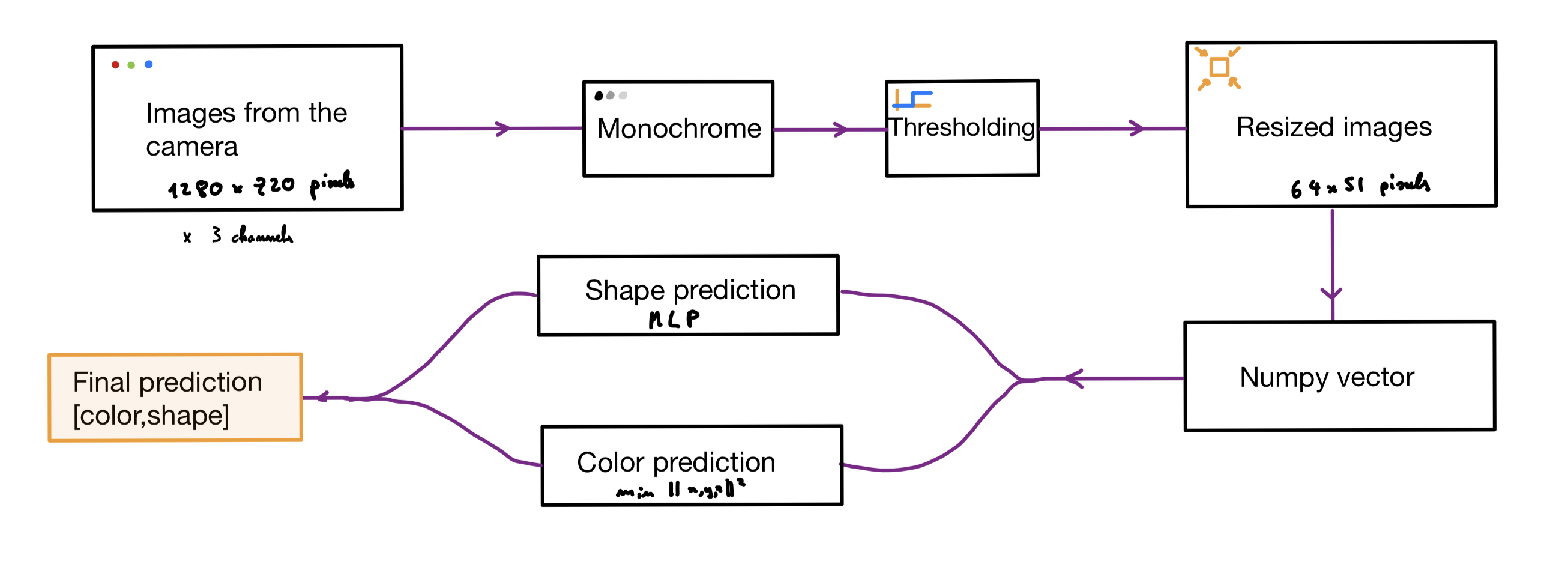
Image preprocessing
In our case, we started with an image from the camera that has a size of 1280×720 pixels, to preprocess the image for shape recognition here is the different steps involved :
Conversion to Grayscale:
The RGB image is transformed into a grayscale image. This conversion reduces the image to a single channel, simplifying the subsequent analysis.
Thresholding:
Low-intensity pixels are thresholded, separating them from the rest of the image. By setting a threshold, this operation enhances contrast and emphasizes the boundaries of shapes, making them more distinguishable for recognition algorithms.
Resizing:
The image is resized to a smaller size of 51×64. This step reduces computational complexity and allows for efficient processing. Despite the reduction in dimensions, the resizing ensures that crucial shape details are preserved, enabling accurate identification.
Here is the processing scheme applied to an image from the camera :
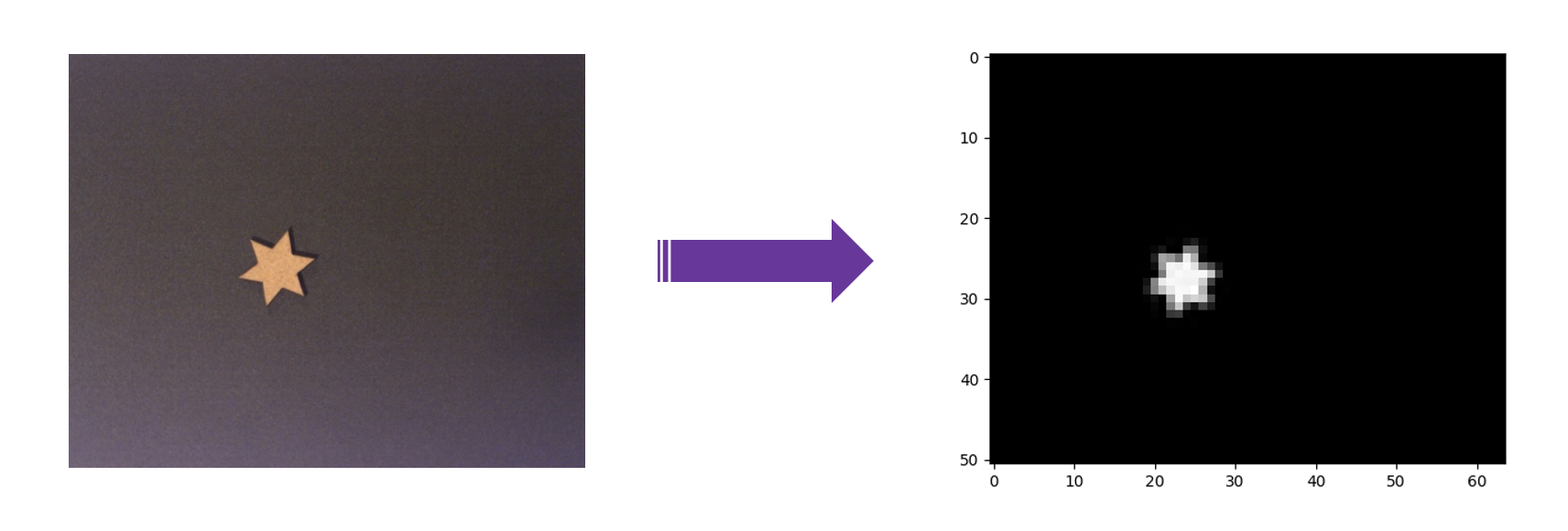
By extracting and simplifying essential information from the original image, the preprocessed image becomes more suitable for the neural network.
Model design
In order to predict the shape and color of an image captured by the camera, a series of preprocessing steps are carried out. The incoming image undergoes preprocessing and is transformed into a feature vector. This feature vector is then fed into a Multilayer Perceptron (MLP) model from the scikit-learn library.
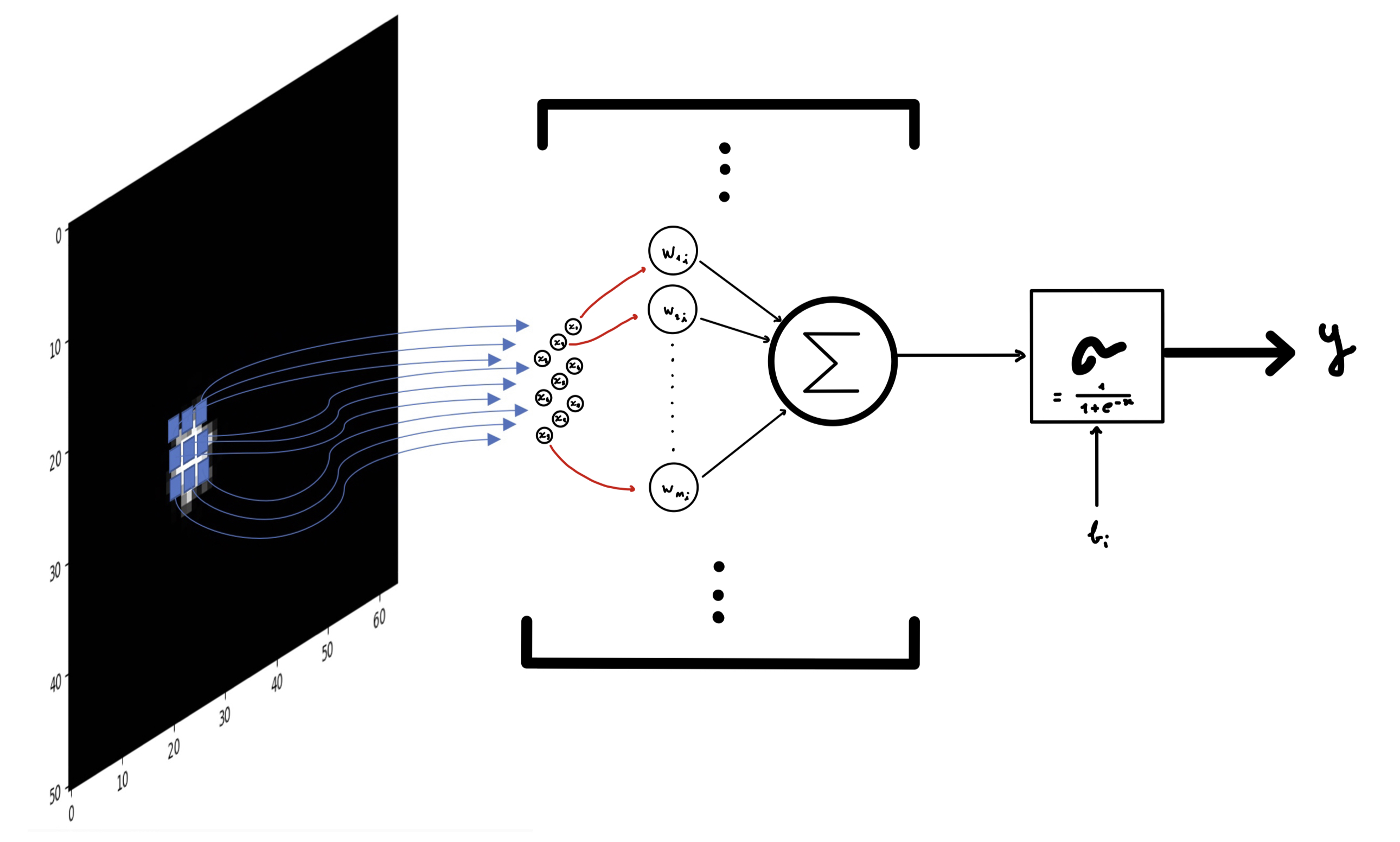
Tip
To train this model we used the IA_training module
And to create the data base we used the Create_DDB module, and generated 91 000 images
Simultaneously, the image is also passed through a color recognition function that estimates the color based on the least square distance of the color RGB vector.
Tip
For this matter, we used the IAcouleurs class
By employing these parallel processes, the system then generates a prediction with the color and shape of the image. The prediction is presented as a result in the form ‘[color, shape]’.
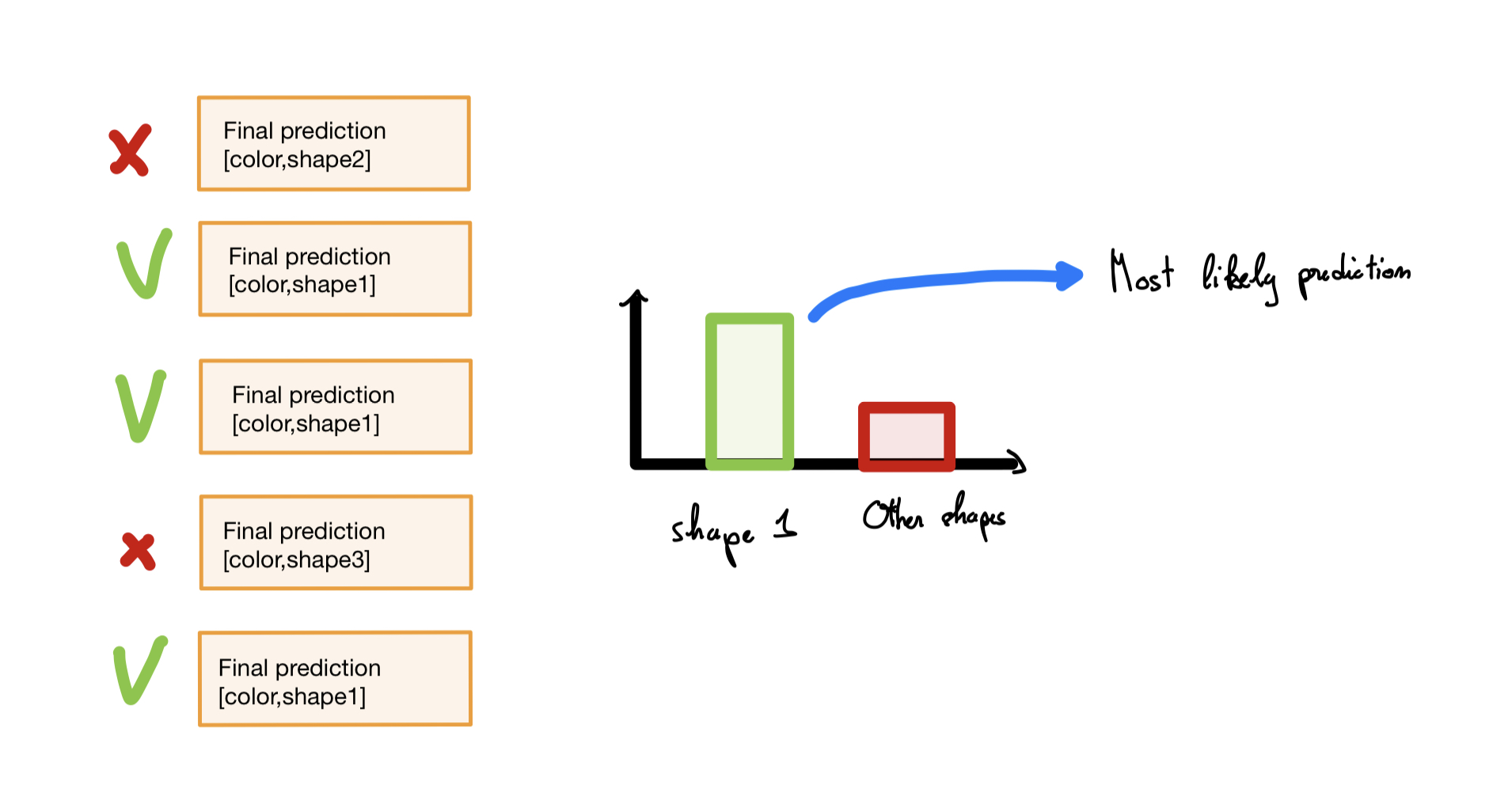
This process is detailed in the diagram below :
To ensure high precision, we leverage the multiple images captured as an object passes in front of the camera. For each image, a prediction is calculated, taking into account both the shape and color of the object. During the acquisition window, the prediction that appears most frequently is selected. This chosen prediction is then fed to the Arduino card, which controls the movement of servomotors accordingly. By considering a series of predictions and selecting the most consistent one, we enhance the accuracy of the system and enable precise adjustments of the servomotors based on the identified object characteristics.